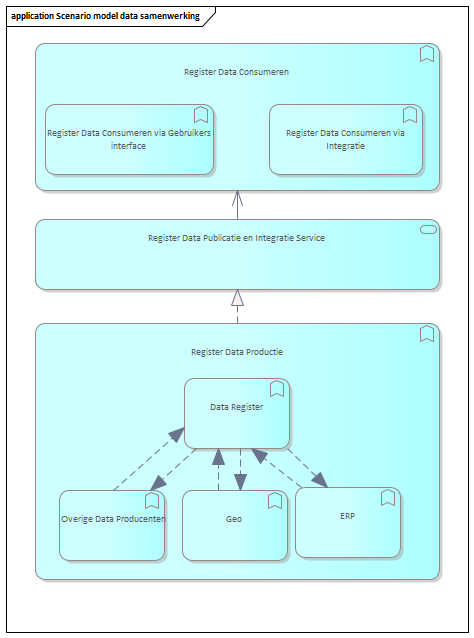
In dit scenario werkt het masterdataregister samen met de verschillende dataproducerende applicatiefuncties. Dit betekent dat wanneer gegevens in een van de systemen worden gewijzigd, deze wijzigingen worden gedeeld tussen alle samenwerkende functies. Daarom is de integratie tussen deze dataproducenten essentieel in dit scenario
Een interessant scenario hierbij is dat het Dataregister alleen als sleutelarchief of sleutelkast wordt gebruikt en de detailgegevens in de andere bronsystemen worden bewaard.
Voordelen:
- Gegevens worden rechtstreeks uit bronsystemen verzameld en zijn dus altijd nauwkeurig en realtime.
- Gegevens kunnen in de bronsystemen worden opgeslagen in een specifiek formaat dat de bedrijfsprocessen binnen deze systemen ondersteunt
- Verschillen in beschikbaarheid tussen consumenten en bronnen kunnen worden opgevangen door het Dataregister
- Hergebruik van schermen, workflows en validaties in de bronsystemen
- Datastandaardisatie binnen het Dataregister
- Introductie van een sleutelkast of sleutelkast.
Nadelen:
- Het beheren van de synchronisatie tussen systemen is extra werk en complexiteit.
- Replicatie van gegevens
- Complexe datatransformaties van bronnen naar register en terug